Paper Overview
Title: A Framework for Human Evaluation of Large Language Models in Healthcare Derived from Literature Review
Authors: Thomas Yu Chow Tam, Sonish Sivarajkumar, Sumit Kapoor, Alisa V. Stolyar, Katelyn Polanska, Karleigh R. McCarthy, Hunter Osterhoudt, Xizhi Wu, Shyam Visweswaran, Sunyang Fu, Piyush Mathur, Giovanni E. Cacciamani, Cong Sun, Yifan Peng, and Yanshan Wang
Journal/Conference: npj Digital Medicine
Year: 2024
DOI/Link: https://doi.org/10.1038/s41746-024-01258-7
This scoping review analyzes 142 studies of human evaluation for healthcare LLMs and argues that current practice is inconsistent, under-specified, and often too weak for high-risk clinical use cases.
Selected Figures
Figure 1. Healthcare applications of LLMs
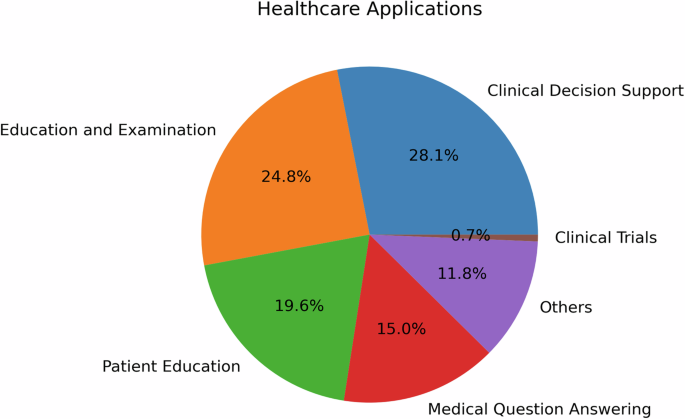
This figure shows where human evaluation has been used most often: clinical decision support, medical education, patient education, and question answering.
Figure 7. QUEST human evaluation framework

This is the most important figure in the paper because it turns the review findings into a practical evaluation workflow.
Figure 9. PRISMA flow diagram

This figure summarizes the literature search and screening process behind the 142 included studies.
Why This Paper?
I read this because it directly addresses a problem that keeps coming up in medical AI:
- we want LLMs to be useful in healthcare,
- but automatic metrics are not enough,
- and human review is often done in a way that is not rigorous enough.
This is especially relevant for clinical decision support, where the risk is high and the cost of weak evaluation is much larger than in a normal consumer app.
Key Findings
Main Contributions
- The authors performed a scoping review of 142 studies on human evaluation of healthcare LLMs.
- They found major methodological gaps: limited blinding, inconsistent comparison baselines, and small evaluator counts in high-risk settings.
- They proposed QUEST, a structured framework for more standardized human evaluation in healthcare.
Methodology Highlights
- Approach: Scoping review following PRISMA-ScR style reporting
- Coverage: English peer-reviewed studies from 2018 to 2024
- Novel Aspects: The review does not just criticize current practice; it turns the findings into an actionable evaluation framework
My Takeaways
Immediately Applicable
- High-risk clinical AI should not be validated with tiny expert panels and loose review criteria.
- Blinded human evaluation matters more than it is often treated in practice.
- If a system is meant to support real clinicians, the evaluation must include usefulness, not only correctness.
- Human evaluation should be planned like a protocol, not treated as an informal afterthought.
Future Exploration
- Use QUEST-like dimensions when designing future evaluation rubrics
- Compare how much expert agreement can be achieved with better reviewer instructions
- Build lighter-weight but still rigorous evaluation workflows for local clinical AI projects
Questions & Critiques
Questions Raised
- How much of QUEST is directly transferable across institutions with very different workflows?
- What is the minimum reviewer set that still produces trustworthy results in practice?
Potential Limitations
- The framework is broad and may still need local adaptation
- Evaluation quality is constrained by available experts and time
- A good framework does not automatically solve the labor cost of human review
Implementation Ideas
For Current Projects
- Project: clinical LLM evaluation workflow
- Application: use QUEST categories to structure a review form
- Timeline: before running the next internal model review
New Project Possibilities
- A lightweight rubric generator for healthcare LLM review
- A reviewer training checklist for human evaluation in clinical AI
Related Work
Papers to Read Next
- Evaluation of generative large language models in stroke care
- Papers on human evaluation methods for clinical LLMs and medical QA systems
Connections to Previous Reading
- Connects well with other notes on healthcare LLM evaluation, RAG systems, and clinical decision support
Rating & Recommendation
My Rating: ⭐⭐⭐⭐⭐
Recommend for:
- Healthcare AI researchers
- Clinical informatics teams
- Engineers building medical LLM systems
- Anyone designing human evaluation workflows for high-stakes AI
Time Investment: A solid paper review session, plus extra time to think through how to apply the framework locally
Reference
- The blog post summarizes a literature review on human evaluation of large language models in healthcare and introduces the QUEST framework.
- Source article: https://www.nature.com/articles/s41746-024-01258-7
- DOI: https://doi.org/10.1038/s41746-024-01258-7